为什么有的下载能接着下,有的断了就得重来?¶
一、引言:从浏览器下载说起¶
你可能遇到过这样的情况:
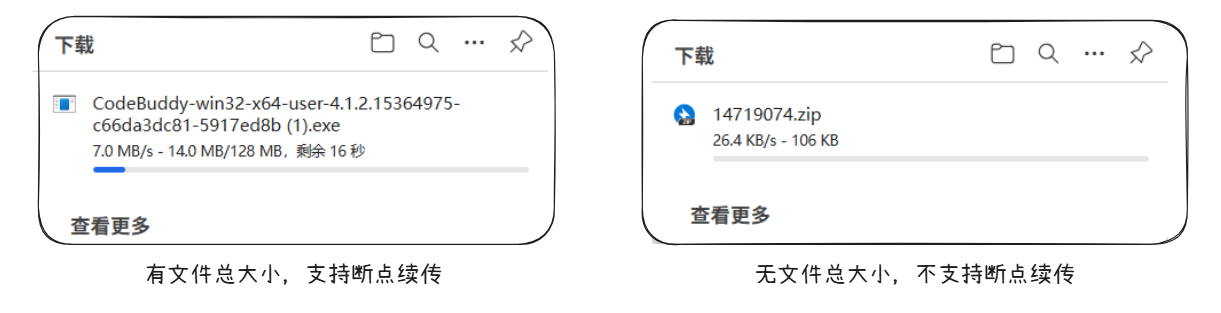
场景 1
你在 Hugging Face 上点击下载一个 10GB 的数据集。浏览器进度条清晰显示:“8.2 GB / 10 GB”。突然网络断了——没关系。几小时后重连,刷新页面或点击“继续”,下载从 8.2GB 处接着跑,像什么都没发生。
场景 2
你点开另一个科研平台的“导出数据”链接,进度条只写“已下载:3.5 GB”,没总大小,没剩余时间。你刚去泡了杯咖啡,回来发现浏览器卡死。重新打开链接?进度清零,从 0 开始。那 3.5GB,白下了。
🤔 那么问题来了:
- 为什么有的下载能看到“总大小”,有的看不到?
- 是不是只要看到总大小,就一定能断点续传?
- 背后到底是谁在控制这个行为?
这些答案不在浏览器,而在提供文件的那一端——服务器。接下来我们从用户的实际体验出发,浅浅地往下走一步,看看背后最直接的原因是什么。
二、用户能观察到的两个线索¶
对普通用户来说,判断一个下载是否支持断点续传,主要看两点:
-
进度条是否显示总大小
比如 “8.2 GB / 10 GB”。如果只显示“已下载 3.5 GB”,没有总长度,通常意味着系统还不知道文件最终有多大。
-
中断后是否有“继续”或“恢复”选项
有时浏览器在下载中断后会保留临时文件,并在重新访问时提供“继续下载”按钮;有时则直接清空,只能重来。
这两个现象看似是浏览器的行为,其实都由服务器决定:
- 能显示总大小,说明服务器在一开始就知道文件全长;
- 能继续下载,说明服务器允许从中间某个位置开始发送数据。
用户不需要懂技术细节,但只要留意这两个线索,就能大致预判:这次下载,断了是不是白下。
三、背后的关键:服务器是否“准备好了”¶
接下来我们往前走一步,看看为什么背后的原因。
当浏览器尝试续传时,它会告诉服务器:“我已经有了前 8.2GB,请从后面接着发。” 但服务器能不能照做,取决于它手里的文件是什么状态。
情况一:文件已经完整存在
比如 GitHub Releases、Hugging Face 或 AWS S3 上的公开文件。这些服务直接把文件放在磁盘上,Web 服务器(如 Nginx)可以随时读取任意位置的内容。因此:
- 它知道文件总长,能告诉浏览器;
- 它支持“从第 N 字节开始发”,所以能续传。
情况二:文件正在动态生成
比如你点“导出我的实验结果”,后端程序一边查数据库,一边拼接 CSV 并实时输出。这种情况下:
- 服务器自己也不知道最终文件多大,所以无法提供总长度;
- 数据是“边算边发”的,没法跳到中间某处重新开始。
虽然理论上可以通过缓存或偏移重放实现续传,但这会显著增加系统复杂度——除非特别设计,没有系统会这么做。
这对应了两种下载方式:静态文件下载和动态流式下载。前者像从书架拿一本现成的书,后者像现场为你手抄一本书——前者天然支持续传,后者则很难。一旦连接中断,整个生成过程就得重来,这不是浏览器不想续,而是服务器没这个能力。 换句话说:能续传的下载,背后是一个“已经准备好的文件”;不能续传的,往往还在“生成中”。
在 HTTP 协议中,这种“准备好”的状态,会通过两个响应头体现出来:
- Content-Length:表示文件总共有多少字节;
- Accept-Ranges: bytes:表示服务器允许客户端请求从某个字节位置开始的内容。
浏览器正是根据这两个信号,决定是否显示“总大小”和提供“继续下载”功能。
四、回到开头的问题¶
现在我们可以回答引言中提出的三个问题了:
1. 为什么有的下载能看到“总大小”,有的看不到?
取决于服务器是否返回了 Content-Length。
- 如果文件已存在(如静态托管),服务器知道总字节数,就会提供这个值;
- 如果文件是动态生成的(如实时导出),服务器无法预知长度,就不会返回它。
2. 是不是只要看到总大小,就一定能断点续传?
不一定。
显示总大小只说明服务器知道文件长度,但续传还需要另一项能力:支持按字节范围请求。
这由 Accept-Ranges: bytes 声明。如果服务器没有返回这个头,即使有 Content-Length,浏览器也无法安全地“接着下”。
3. 背后到底是谁在控制这个行为?
是服务器。
浏览器只是被动响应:当它看到 Content-Length 和 Accept-Ranges: bytes 同时存在,才会启用续传功能;否则,只能从头开始。
所以决定你能否“断点续传”的,从来不是网速或浏览器,而是服务器是否把文件当作一个完整的、可随机访问的对象来对待。
五、实用建议:如何避免白下几 GB?¶
断点续传不是玄学,而是一种可预判的服务能力。作为下载者,你可以通过以下方式降低“白下”风险:
-
优先选择静态托管链接
域名如.huggingface.co、.s3.amazonaws.com、github.com/releases等,几乎都支持续传——因为它们提供的是已经存在的文件。 -
对“导出”“生成”类链接保持警惕
尤其是内部系统、科研平台或小众工具中的“导出数据”“下载报告”按钮。这类链接背后往往是实时计算,一旦中断,进度清零。 -
下载开始后,快速确认是否支持续传
按F12打开浏览器开发者工具 → 切到 Network 面板 → 找到下载请求 → 查看响应头:- 如果有
Content-Length和Accept-Ranges: bytes,说明可以续传; - 如果看到
Transfer-Encoding: chunked或缺少上述两项,建议尽量保持连接稳定,避免中断。
- 如果有
-
如果你恰好也负责发布数据
尽量使用静态文件托管;若必须动态生成,请确保后端能正确处理“从第 N 字节开始”的请求——这对用户非常友好。
结语¶
你没法续传一个正在诞生的东西——除非它愿意等你。