LLM 学习:RAG¶
年末回顾这一年时,突然感觉已经开始落后于时代。一直在做着科研,但所研究方向和主流渐行渐远;一直在尝试使用 ai 工具提高效率,但总是对其背后的技术仍是一知半解。这么一年过去,惊觉自己已经错过了太多。为了避免脱离时代,新的一年就以学习当前 LLM 的相关技术开始。
25/05/26: 发现只是开了个头,然后就又陷入到找实习和项目结题的漩涡了
。感觉当时的想法也比较模糊,不太清楚到底想做什么。现在看来,这个系列的主题应该是通过一些小 Demo 学习新东西、新概念。先跑别人的 Demo,知道一个东西工作起来应该是什么样,再跟着教程写个 Demo,了解做这个东西的基本步骤。总之,先了解用户能得到什么,再浅浅地探一下开发者是怎么做的。
RAG(Retrieval-Augmented Generation,检索增强生成)是一种通过结合检索技术来提升大语言模型(LLM)回答质量的技术框架。其在 Facebook 在 2020 年发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》 中被提出,应用于知识敏感的 NLP 任务,如知识问答。
RAG 将问题求解划分为检索和生成两阶段,先通过检索,查找与问题相关的文档,再将文档和问题一并输入模型,由模型推理给出最终的答案,从而解决模型无法扩展知识和产生“幻觉”的问题。
为什么需要 RAG?¶
LLM 的回答主要依赖于两类知识:首先是参数化知识,即模型通过训练学习到的、存储在参数中的知识,这些知识主要来源于训练时使用的海量网络数据;其次是非参数化知识,即上下文中的信息,包括当前对话的提示词和历史内容,这部分完全依赖于用户输入。然而,当问题涉及特定领域或本地化知识时,LLM 的上下文窗口往往显得捉襟见肘,容易导致模型产生“幻觉”现象。RAG 技术通过引入检索机制,能够更高效地利用上下文窗口,让 LLM 的回答更加准确和定制化,从而有效缓解这一问题。
RAG 原理¶
论文为了将流程描述清楚使用了一些符号,但不做这方面的研究的话其实不需要把概念理的很清。要理解 RAG 的原理并不难,其做法可以说是符合直观的。
RAG 的思路是:当用户提出一个问题时,系统首先从知识库中检索出与问题最相关的文档片段,然后将这些文档片段与问题一起输入到语言模型中,由模型生成最终的答案。然后,为了衡量文档片段的相似度,会使用向量检索技术,通过词嵌入将问题和文档片段都转换为向量表示,并通过计算向量之间的相似度来找到最相关的内容。参考下图:
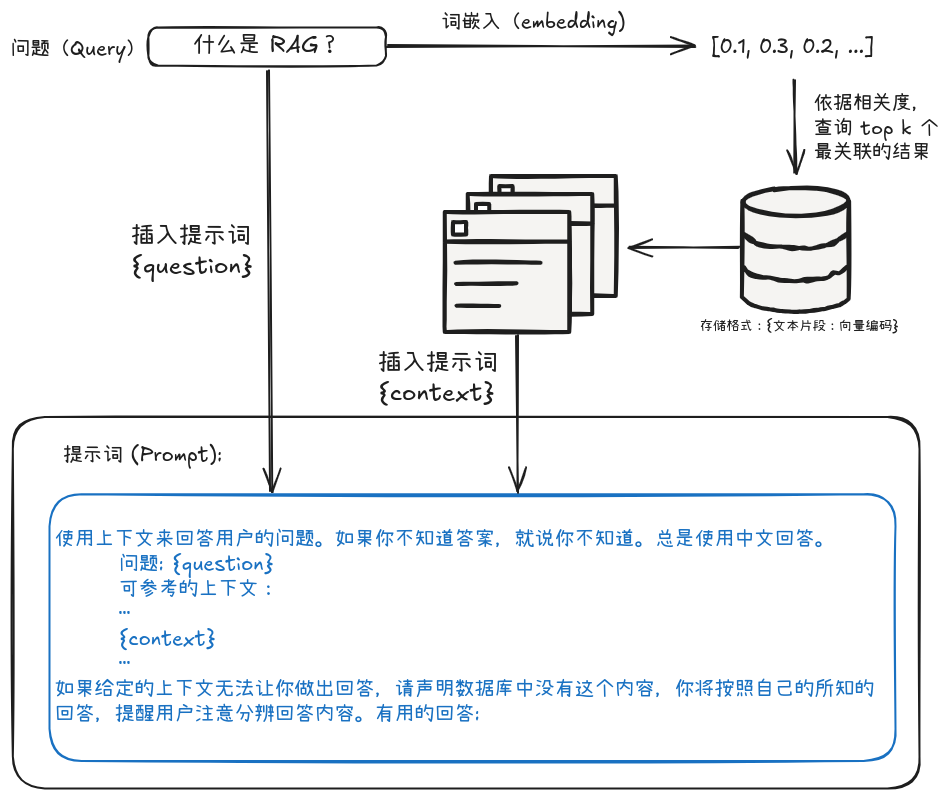
RAG 提示词生成流程
部署一个简单的 RAG¶
Kent Beck
Make it work, make it right, make it fast.
遵循 MMM 原则,计划先让 RAG 在我的服务器上工作起来。在这一点上 Datawhile 的 TinyRAG 项目就很合适。理论上在服务器上跑通 TinyRAG 后给它做成一个 systemd 服务自动运行就可以了。不过 2核2G 的服务器配置还是太捉襟见肘了,甚至难以在本地进行词嵌入处理。所以最终采用了全 API 方案:词嵌入通过调用智谱AI的 API 来完成,对话模型调用近期备受关注的 DeepSeek-v3 的 API 来实现(主要是注册送的免费 token 多)。
2025/01/21 补充:发现 ChatGLM-Flash 不要钱,不过回答质量有点不稳定,先保持不变。
确定了技术方案后要做的事情就清晰多了,先上对应平台申请 API Key 配置到 .env 文件中,然后对代码做一些简单的微调,主要是添加 DeepSeek v3 作为对话模型。这里得益于 DeepSeek 对 OpenAI API 的全面兼容1,我们可以简单的复用原代码中 OpenAIChat 的部分来实现:
方案跑通后就可以着手设计接口了。做为起步的 MVP 只包含一个最小的功能:单次问答。用户给出一个问题,模型给出回答,结束。这样实现起来就很容易了,先取出请求中的问题,然后调用写好的方法得到回答,再把回答写回链接就行:
最后,创建 Systemd Unit 文件,将这个整个项目做成一个 systemd 服务:
| /etc/systemd/system/tinyrag.service | |
|---|---|
现在,TinyRAG,启动!
$ sudo systemctl daemon-reload # 重新加载 Systemd Unit 文件
$ sudo systemctl restart tinyrag # 启动 tinyrag 服务
$ sudo systemctl enable tinyrag # 设置 tinyrag 服务开机启动
简单测试了两个情况2:
case1: 检索命中

case2: 检索未命中

通过上面两个简单的测试可以看出,TinyRAG 运行良好,实现了预期的功能。
-
这种兼容使得我们可以在许多 AI 应用中替换 ChatGPT,参考这个项目:awesome-deepseek-integration。(要搞个能用的 OpenAI API Key 太难了 QAQ。) ↩
-
随着文档的变更,截图中问题的答案已经不再准确了,这里只是在展示 RAG 带来的变化。 ↩